
Web Server Logs, SEO and Science
When you talk with SEO consultants or in general with people about SEO, you often hear them saying "SEO is not an exact science" ,"Search engines are driven by algorithms which are updated constantly, it is impossible to follow them" , "Nobody can fully understand how google works even the engineers who are working on it". I could agree with all those statements only if the web server logs do not exist.
There is one simple fact everyone whether being an SEO professional or not will confirm is "If a page is not crawled by a search engine bot, it can not bring in any organic visits from that search engine". This basic truth alone is the entry point of SEO in science. Although we can not completely perceive how google as a search engine works, there is a way to find out how google perceives a website entirely by analyzing that website's web server logs.
Web server logs can answer two important questions.
In a certain period of time which pages of the website
- Have been crawled by a search engine bot.
- Are bringing in organic traffic by that search engine.
Web server logs are the best, in fact the only place where you can check and have insights about how your crawl budget is spent.
Introduction to Web Server Logs
What is a server?
A server simply is a computer which provides data to other computers.
Many types of servers exist, including web servers, mail servers and file servers.
What is a web server?
In computer science, the term "web server" refers to both a physical machine and software.
In the first case, it is a computer connected to the Internet and hosting resources. These resources can be files, programs or databases.
In the second case, a web server is a set of programs which operate and publicize a website or web application.
What are the popular web server softwares?
 |
Apache • Open Source • PHP,Perl, Python, Ruby • Linux,Unix, Windows, Apple OS X |
 |
NGIN-X • Open-Source • PHP, Perl, Python, Ruby • Linux,Unix, Windows, Apple OS X |
 |
IIS • Commercial • ASP.NET • Windows |
How to identify a web server software?
It is essential to know which web server software is running on a web server of a website before analyzing its logs.
There are several methods
1) Curl
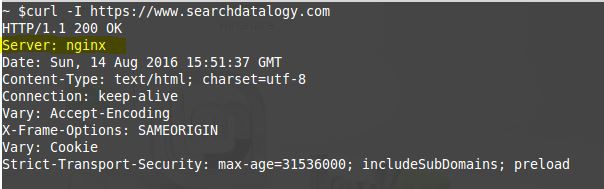
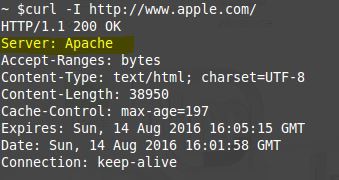
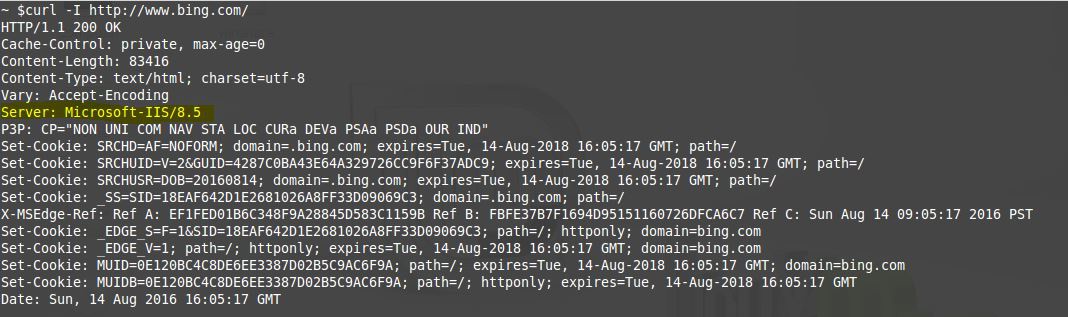
2) Live HTTP Headers
On Chrome or Firefox, with this add on, it is possible to get HTTP headers of a page on a browser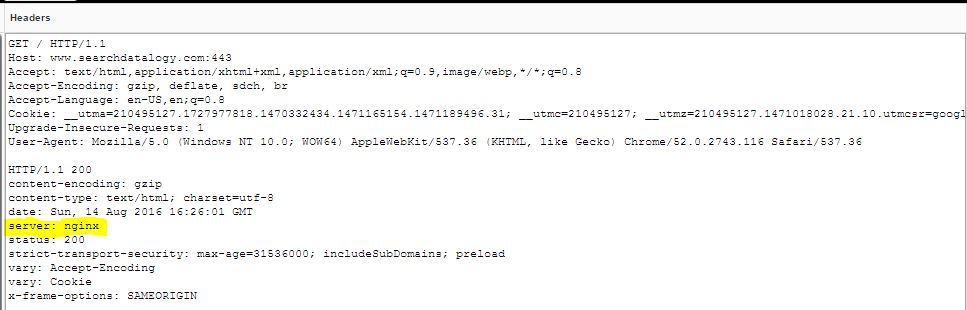
3) Online Tools
Netcraft.com
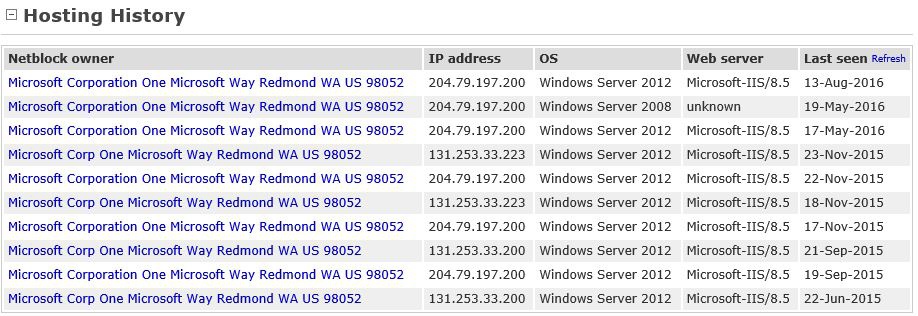
Netcraft is also good for learning about the history of used web server softwares on the web server.
http://toolbar.netcraft.com/site_report?url=www.bing.com
Builtwith.com
Builtwith is also handy to have an overall idea about the technologies used on the website as well as the web server software on the web server

What Is A Web Server Log File?
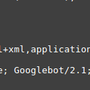
A web server log file is a file which keeps track of all requests that are sent to that web server. The requests can come from humans through browsers or from bots (like search engine bots) through crawlers. Each requests either from humans or robots produces a single line of code in these files. Web server log files are also very useful to analyze the audience of a website because they provide precise information on site traffic.
What Does A Web Server Log File Look Like?
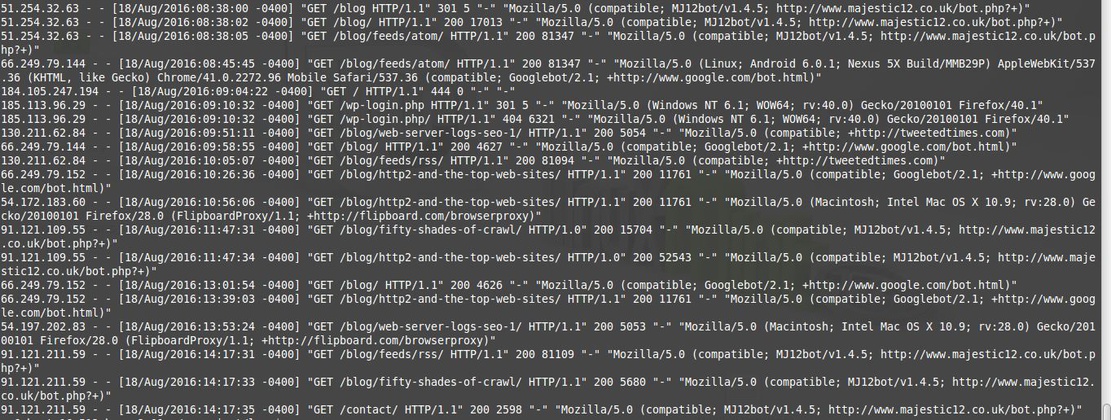
What Is The Information In One Line Of A Web Server Log File?

Web Server Softwares and Web Server Logs Format
|
http://httpd.apache.org/docs/current/logs.html#accesslog |
|
http://nginx.org/en/docs/http/ngx_http_log_module.html |
|
https://www.microsoft.com/technet/prodtechnol/WindowsServer2003/Library/IIS/676400bc-8969-4aa7-851a-9319490a9bbb.mspx?mfr=true |
Why Do We Need Web Server Log File Analysis For SEO?
| Any analytics tools provide information about the pages bringing visits to a website but none of them provide complete information about the pages which are crawled by search engine bots. | |
 |
The information given about indexed pages of a website from google is not accurate, besides it is not possible to access or extract those pages completely. |
 |
The only tool that gives information on google crawl is Google Search Console but ... |
Why Google Search Console Is Not Sufficient For SEO?
 |
| In SEO what we focus on is the contents and the strategical contents crawl by googlebot. |
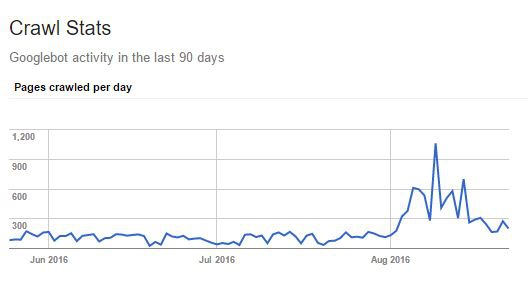
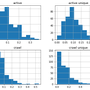
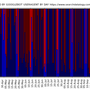
1) However at Search Console on crawl stats graph we see the crawl of all the google bots and all web elements crawls (css, javascript, flash, pdf, images) on a web site.
 |
2) We can not identify the status code of the crawled web pages on that crawl stats graph.
3) The crawl stats graph shows unique crawl but in SEO we would like to know how frequently (or how many times) a certain page or some pages are crawled too.
4) Crawled pages by googlebot can not be accessed or extracted from Search Console therefore we can not
- Categorize them
- Analyze them
- Keep historical crawl data
5) We do not have access to all active pages ( pages receiving organic search engine visits) data. In Search Console we only have access to pages bringing Top and Middle Tail traffic, we do not have access to the active pages bringing in long tail traffic.
Thanks for taking time to read this post. I offer consulting, architecture and hands-on development services in web/digital to clients in Europe & North America. If you'd like to discuss how my offerings can help your business please contact me via LinkedIn
Have comments, questions or feedback about this article? Please do share them with us here.
If you like this article















Comments