Viewing posts for the category SEO Data
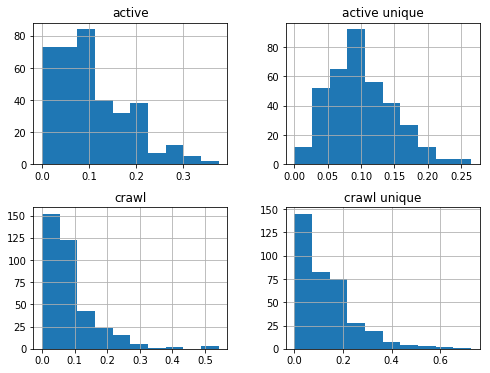
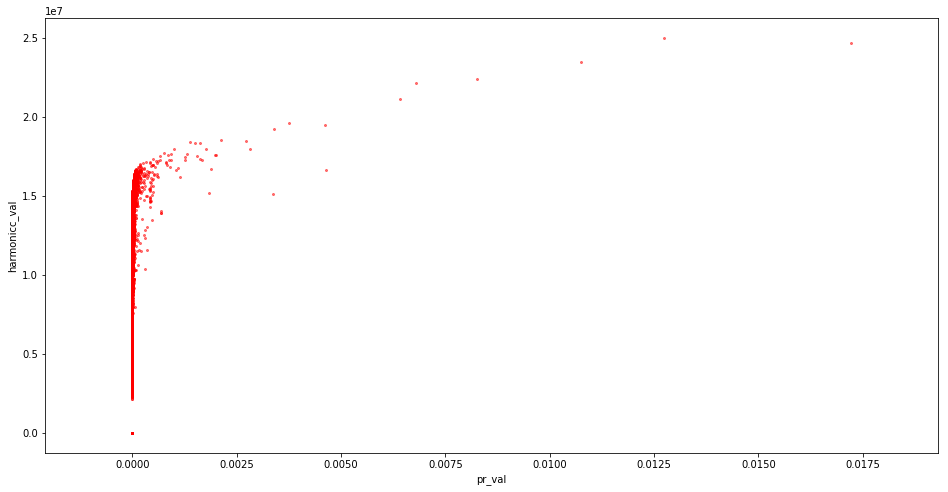
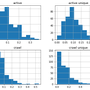
87 million domains pagerank
87 million domains pagerank and harmonic centrality
When we search "Common Crawl" on google, knowledge graph states that "Common Crawl is a nonprofit 501 organization that crawls the web and freely provides its archives and datasets to the public. Common Crawl's web archive consists of petabytes of data collected since 2011. It completes crawls generally every month. Common Crawl was founded by Gil Elbaz."
read more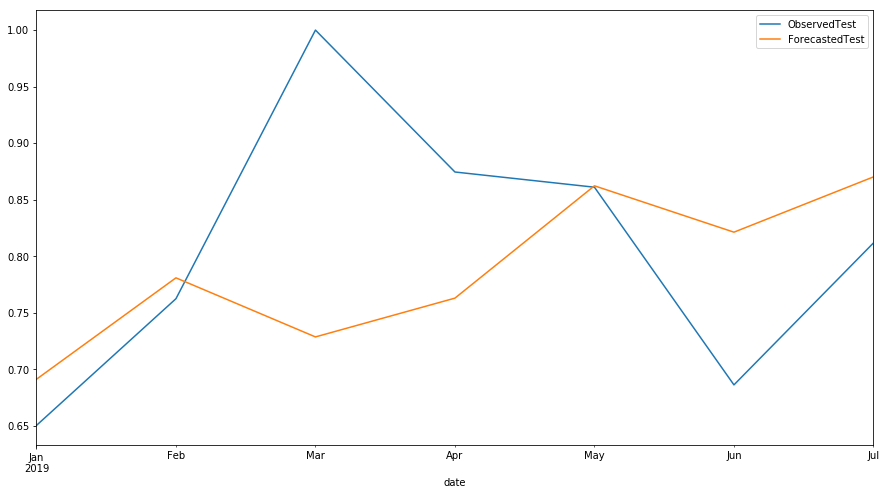
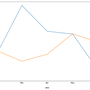
SEO Forecasting
SEO Forecasting
This blog post is published first on 2018-10-22 and updated on 2023-03-07.
read more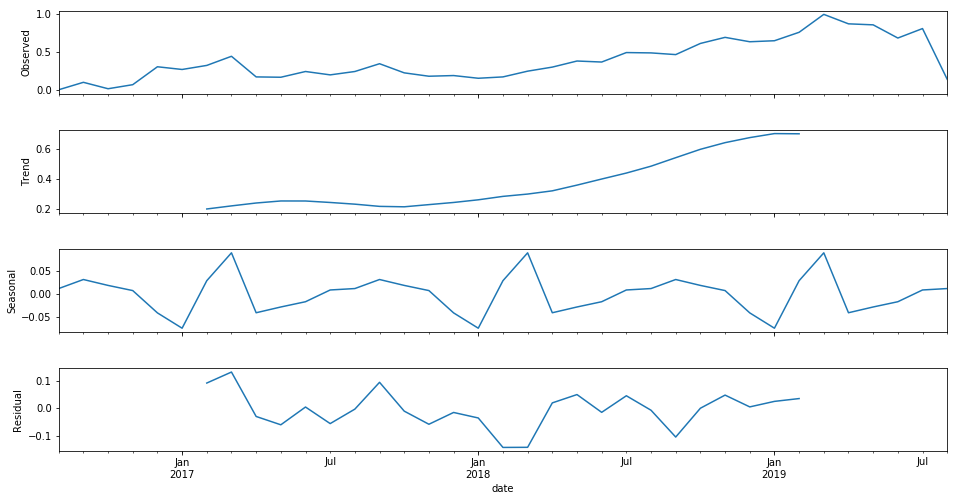
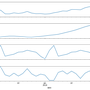
SEO data analysis
SEO data analysis
This blog post is published first on 2018-10-18 and updated on 2019-08-20.
read more
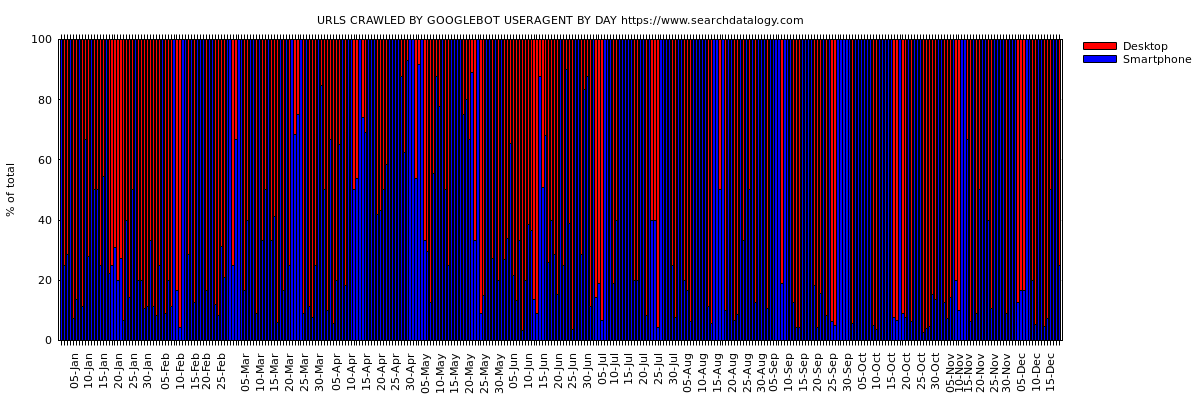
Is my site in google's mobile first index?
Is my site in google's mobile-first index?
Your site's web server logs will answer the question
As we know few sites have already moved to google’s mobile-first index.
read more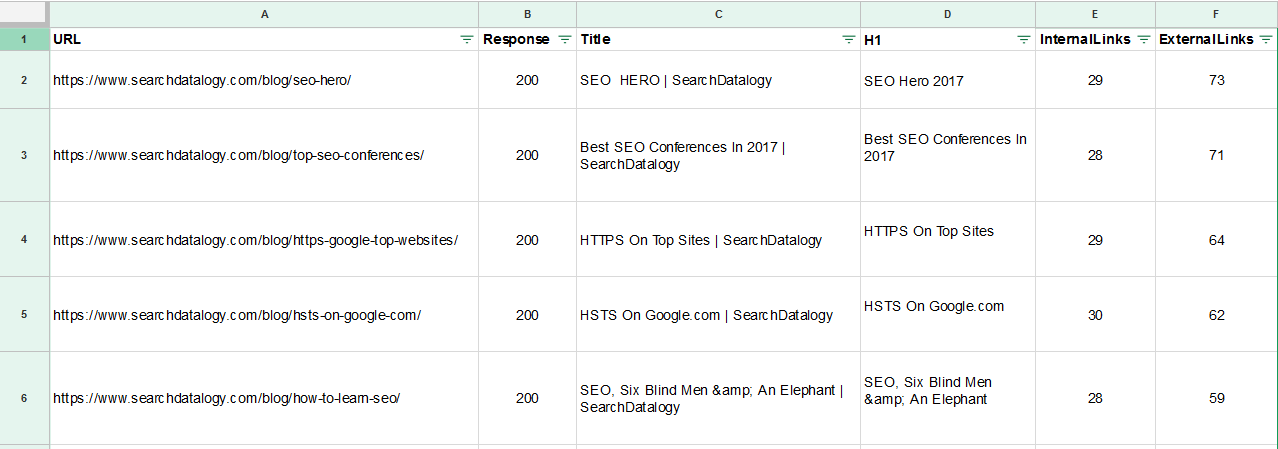
Free SEO tools with google app script
Free SEO Tools on Google Sheets with Google App Script
Google Sheets have many restrictions, quota limits however they can still be helpful in daily SEO tasks especially if you have a small website or else if you want to check SEO data quickly on small number of URLs.
read more
1 million #SEO tweets
1 Million Unique #SEO Tweets
I have collected 1 Million unique tweets with the hashtag SEO, actually more than 1 Million, precisily 1 111 035 tweets.
read more
Technical SEO log analysis
Technical SEO Log Analysis On Linux
Web Server Logs Analysis is the essential part of Technical Search Engine Optimization. Without analyzing the valuable data in log files any Technical SEO Audit will be incomplete. It is the only place where you can get accurate information about how search engine bots are crawling your website and on which pages of your site they are sending search engine users.
read more
SEO web server log files
Web Server Logs, SEO and Science
When you talk with SEO consultants or in general with people about SEO, you often hear them saying "SEO is not an exact science" ,"Search engines are driven by algorithms which are updated constantly, it is impossible to follow them" , "Nobody can fully understand how google works even the engineers who are working on it". I could agree with all those statements only if the web server logs do not exist.
read more